Vector-Based Internal Linking: How Embedding Models Find Semantic Matches
Vector-based internal linking uses embedding models — transformer-based neural networks such as BERT, SBERT, or E5 — to convert web pages into dense, high-dimensional vectors (typically 384 to 1,536 dimensions) and identify semantically related pages by computing cosine similarity between those vectors. Unlike keyword-matching systems that require exact anchor text overlap, vector-based matching captures topical relationships between concepts even when no shared vocabulary exists.

A cosine similarity threshold of 0.65–0.75 is the standard working range for distinguishing semantically related pages from unrelated ones. Scores above that threshold flag pages as candidates for internal link insertion. This is not an experimental approach: Google’s Karpukhin et al. (2020) paper “Dense Passage Retrieval for Open-Domain Question Answering” confirms that embedding-based retrieval is a production-grade signal in modern search — the same mathematical logic underpins how Google understands topical relationships at scale.
Embedding models power the semantic layer in LinkBoss’s Contextual Semantic Interlinking feature, which combines proprietary contextual NLP with a hybrid embedding architecture to surface paragraph-level link opportunities weighted by content quality — a meaningful departure from static keyword-match rules that ignore topical nuance entirely.
What Is Vector-Based Internal Linking?
Traditional internal linking tools suggest links based on exact or LSI keyword matches — requiring the anchor phrase on a source page to share words with the target term on a destination page. Vector-based internal linking replaces this logic with semantic understanding derived from neural embedding models. Four properties define the approach: Contextual link examples for SEO can enhance user experience by providing relevant information that matches the reader’s intent. By using semantic connections rather than strict keyword alignment, websites can improve their ranking potential organically. This approach not only optimizes search visibility but also encourages deeper engagement from visitors.
- Dense vector representation — each page is encoded as a numerical vector in a high-dimensional embedding space, where semantically similar pages cluster together regardless of shared vocabulary.
- Contextual meaning over lexical overlap — a page about “PageRank sculpting” and a page about “link equity distribution” score high in vector space even without a single shared anchor word.
- Cosine similarity scoring — the mathematical operation that measures directional alignment between two vectors. Higher scores indicate stronger topical relationships.
- Symmetric matching — unlike PageRank’s unidirectional link graph, vector similarity is bidirectional: if page A is similar to page B, page B is equally similar to page A by the same score.
This matters for internal linking because it surfaces contextual opportunities that keyword-based systems permanently miss — particularly between pages covering adjacent or complementary subtopics that share no anchor text overlap. The AI Internal Linking hub covers how this fits within the broader shift from lexical to semantic ranking signals across both search and AI discovery systems.
Why Semantic Matching Outperforms Keyword Matching for Internal Links
Keyword-based linking creates a hard ceiling: you can only connect pages that share vocabulary. Vector-based linking removes that ceiling entirely. The dual-encoder framework described in Karpukhin et al. (2020) demonstrates that dense retriever models outperform BM25 by 9–19% absolute in top-20 passage retrieval accuracy across open-domain QA benchmarks. That gap is not marginal — it reflects a systematic advantage at identifying genuinely related content regardless of surface-level word overlap.
| Dimension | Keyword-Based Linking | Vector-Based Linking |
|---|---|---|
| Anchor text requirement | Exact or partial keyword match required | No keyword requirement |
| Topical coverage | Limited to shared vocabulary | Full topical nuance captured |
| Synonym handling | Misses synonyms and paraphrases | Captures semantic equivalents natively |
| Concept-level relationships | Not detectable | Default behavior |
| Orphan-page detection | Requires explicit link signals | Identifies relationships from content alone |
| Scaling to 1,000+ pages | Accuracy degrades as vocabulary diversifies | Consistent clustering regardless of corpus size |
For large sites running 1,000+ pages, the performance gap between these two approaches is decisive. Keyword density thins as vocabulary diversifies across a growing catalog; embedding models maintain consistent topical clustering regardless of corpus size because they encode meaning rather than count word occurrences.
How Embedding Models Process Pages for Internal Linking
The vectorization pipeline that enables semantic internal linking operates in four stages.
Stage 1: Content Extraction and Preprocessing
The system extracts the full text content from each page — title, headings, body paragraphs, and meta descriptions — and normalizes it: lowercasing, stripping HTML tags, and trimming to a token limit (typically 512 or 768 tokens for transformer models). This produces a clean text sequence that accurately represents the page’s topical content without markup noise.
Stage 2: Contextual Encoding via Transformer Model
A pre-trained transformer model processes the token sequence and produces a dense vector. Common models used in production internal linking systems include:
- BERT-base — 768-dimensional vector; foundational model from Devlin et al. (2018, Google)
- SBERT (all-MiniLM-L6-v2) — 384-dimensional vector; scores 68.9 on the STS benchmark at approximately 5ms per encoding; best balance of speed and accuracy for most self-hosted deployments
- E5-base — 1,024-dimensional vector; state-of-the-art performance on MTEB benchmarks as of 2024 (Wang et al., 2022)
- OpenAI text-embedding-3-small — 1,536-dimensional vector; 62.3% on MTEB; 5x more cost-effective than the previous ada-002 model
The encoding is contextual: each token’s representation is shaped by its surrounding tokens, capturing meaning from sentence and paragraph structure rather than word frequency alone. This is the critical architectural distinction from bag-of-words approaches — “apple” (fruit) and “apple” (technology brand) receive different vectors depending on their surrounding context.
Stage 3: Vector Indexing
Once all pages are vectorized, the collection is indexed in a vector database optimized for approximate nearest-neighbor (ANN) search. FAISS (Facebook AI Similarity Search), developed at Meta’s Fundamental AI Research group, supports L2 (Euclidean) distances, dot products, and cosine similarity on normalized vectors. It scales to billions of vectors on a single server using compressed representations and supports GPU acceleration via CUDA. Alternative libraries include Annoy (Spotify) and Qdrant, each offering different trade-offs between indexing speed, query latency, and memory footprint.
Stage 4: Cosine Similarity Scoring and Thresholding
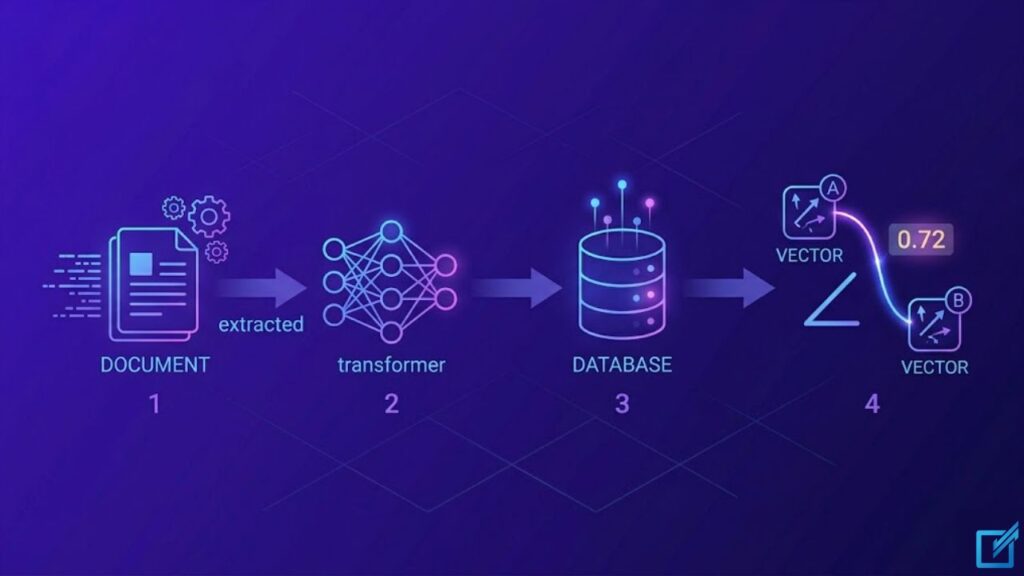
When the system evaluates a source page for link opportunities, it computes the cosine similarity between the source vector and every candidate destination vector:
cosine_similarity(A, B) = (A · B) / (||A|| × ||B||)Scores range from 0 (completely unrelated) to 1 (identical content). Thresholds typically fall between 0.65 and 0.75 for internal linking — high enough to ensure topical relevance, low enough to capture legitimate adjacent-topic coverage. As OpenAI’s embedding documentation states, cosine similarity between normalized vectors is the standard retrieval operation, producing scores in a consistent 0–1 range that maps directly to retrieval confidence.
Why Search Engines Use Dense Retrieval for Ranking
Google’s published research confirms that embedding-based dense retrieval is operational in production search — not experimental:
- Google Search Central states that BERT is used to understand query intent and the contextual meaning of content across more than 40 languages.
- Karpukhin et al. (2020, Google AI) — “Dense Passage Retrieval for Open-Domain Question Answering” — describes Google’s production DPR system used to retrieve relevant passages from a corpus of tens of millions of documents, confirming embedding-based retrieval at Google scale.
- Meta’s SEER (Kwon et al., 2020) confirms that pre-trained contextual embeddings outperform traditional lexical matching on web-scale document retrieval tasks.
The implication for internal linking is concrete. Pages that are semantically related via vector similarity are likely evaluated as related by Google’s own systems. Building internal links between vector-similar pages aligns your site architecture with Google’s topical clustering signals — and the coherence signal from embedding-matched link structures may also strengthen eligibility for AI Overviews and Perplexity citations.
For the full framework connecting semantic clustering to search visibility, see the Topical Authority hub.
Tools That Use Vector-Based Internal Linking
Several production tools implement embedding-based internal linking with varying architectures:
| Tool | Embedding Model | Threshold | Index Scope | Suggestion Method |
|---|---|---|---|---|
| LinkBoss (Contextual Semantic Interlinking) | Proprietary contextual NLP + embedding hybrid | Dynamic, content-quality adjusted | Full site | Paragraph-level with anchor text classification |
| Link Whisper | Keyword + NLP hybrid | Static | Post-level | Sentence-level contextual suggestions |
| Internal Link Juicer | Keyword-based | Static | Category/tag | Auto-links on keyword occurrence |
| Frase | OpenAI text-embedding-3-small | API-configurable | Full site | Content briefing integration |
| AirOps | OpenAI / Cohere embeddings | Configurable | Draft + site | AI writing assistant integration |
| Custom (open-source) | SBERT (all-MiniLM-L6-v2) via FAISS | User-defined | User-defined | Programmatic pipeline |
References: OpenAI text-embedding-3-small release documentation (January 2025); CohereEmbed v3 specification; Wang et al., “E5: A New High-Quality Embedding Model” (2022).
See How LinkBoss Implements Vector-Based Linking →
How to Implement Vector-Based Internal Linking on Your Site
Implementing vector-based internal linking involves a four-stage pipeline. Here is how to approach it systematically.
Step 1: Choose Your Embedding Architecture
Evaluate whether to use a SaaS API (OpenAI, Cohere, Google Vertex AI) or a self-hosted model (SBERT via the sentence-transformers library). SaaS options offer faster setup and managed scaling; self-hosted options provide data privacy and cost control at high volume.
For most teams, the all-MiniLM-L6-v2 model via sentence-transformers provides the best accuracy-to-speed ratio for self-hosted deployments, encoding a passage in approximately 5ms on CPU. If accuracy is the primary requirement and compute budget allows, E5-base or OpenAI text-embedding-3-small offer meaningfully stronger semantic discrimination.
Step 2: Index Your Site Content
Run your CMS content through the embedding pipeline. Most implementations extract the title, H1, H2s, and body text from each URL and generate one vector per page. For large sites (10,000+ pages), batch processing with a queue system prevents API rate limiting and avoids memory overflows during indexing.
LinkBoss’s Bulk Auto Interlinking processes up to 200 URLs simultaneously using vector embeddings for semantic relevance, with a context preview before insertion — eliminating the relevance drift that comes with blind automation at scale.
Step 3: Set a Cosine Similarity Threshold
Start at 0.70. Pairs scoring above this threshold are strong semantic matches. Analyze false positives — high-scoring pairs that are not actually related in your judgment — and adjust:
- Below 0.65: too few suggestions surface; the threshold is too strict
- 0.65–0.75: practical working range for most sites and embedding models
- Above 0.80: suggestions may be too narrow, missing legitimate adjacent-topic links
Step 4: Generate Link Suggestions and Filter by UX
Vector similarity identifies topical relationships; it does not account for link placement quality. Filter suggestions to exclude navigation links, footer links, links within the same paragraph as an existing link to the same destination, and cases where the proposed anchor text would be identical to the destination page’s H1.
The Smart Anchor Text Optimizer provides AI-powered anchor text distribution analysis to ensure that semantic link additions maintain healthy anchor ratios rather than concentrating exact-match anchors in ways that can trigger over-optimization signals.
Step 5: Insert Links and Monitor Performance
Track the CTR and ranking trajectory of pages that receive new vector-matched internal links against a comparable control group. Measure whether semantic link additions correlate with improved indexation depth — measured in clicks-from-homepage — in Google Search Console’s Coverage report.
The Site Visualizer renders an interactive network graph showing every page as a node and every internal link as a visible connection, making it possible to validate that embedding-matched links produce the intended topical clustering structure rather than random noise in the link graph.
Measuring Whether Vector-Based Linking Is Working
Establish a measurement framework before implementation, not after:
- Indexation depth delta — use GSC’s Coverage report to track whether newly linked pages receive more frequent crawling after semantic links are added.
- Rank movement on vector-linked pages — compare ranking changes for pages that received embedding-matched internal links against similar pages that did not.
- AI Overview citation rate — track whether semantically interlinked content clusters surface in AI Overviews for topical queries, using rank-tracking tools that monitor generative engine optimization (GEO) visibility.
- Internal link equity distribution — measure whether PageRank link equity flow (via a tool such as Ahrefs Site Audit) becomes more evenly distributed across the site after implementing vector-based linking.
For deeper context on how the vector approach connects to the NLP classification pipeline, see NLP-Powered Internal Linking: What Actually Happens Under the Hood. For the mathematical foundation behind cosine similarity scoring, see Embeddings & Cosine Similarity for SEO: The Math Behind Smart Anchor Suggestions.
Frequently Asked Questions
What is vector-based internal linking in SEO?
Vector-based internal linking is an approach where an embedding model (such as SBERT, BERT, or E5) converts each page on a website into a dense high-dimensional vector, then uses cosine similarity to identify semantically related pages — regardless of shared keywords — for internal link suggestions. It captures concept-level topical relationships that traditional keyword-matching tools cannot detect.
What cosine similarity threshold should I use for internal linking?
A threshold between 0.65 and 0.75 is the practical working range for most embedding models. Values below 0.65 produce false-positive suggestions between unrelated pages; values above 0.80 may exclude legitimate topical connections. For SBERT-based systems using all-MiniLM-L6-v2, 0.70 is the most commonly cited starting point in published implementations.
Which embedding model is best for internal linking at scale?
For most production deployments, all-MiniLM-L6-v2 (SBERT) offers the best balance of speed (384 dimensions, ~5ms per encoding) and accuracy, scoring 68.9 on the STS benchmark. For higher accuracy requirements where compute cost is acceptable, E5-base (1,024 dimensions) or OpenAI’s text-embedding-3-small (1,536 dimensions) offer superior semantic discrimination.
Does vector-based internal linking replace PageRank-based linking strategy?
No — they operate on different signals and are complementary. Vector matching identifies which pages are topically related (semantic signal); PageRank determines how much authority should flow between them (link equity signal). The most effective internal linking strategies use both: vector matching to decide which pages should link, and link equity analysis to decide how many outbound links each page should carry without diluting authority. This framework is covered in depth in the Topical Authority hub.
How do AI crawlers like GPTBot and ClaudeBot use internal links?
OpenAI’s GPTBot documentation confirms the crawler follows the same anchor tag structure as standard web crawlers and respects robots.txt directives. AI systems additionally use the semantic context of surrounding text — not just the anchor text itself — to determine what a linked page is about. This means internal links placed within contextually rich body paragraphs carry more topical weight for AI citation than links from navigation menus or footers. AI Internal Linking: Agents vs Plugins vs SaaS — Which Architecture Wins? covers how this crawler behavior shapes which internal linking architectures are most effective for AI-driven discovery.
References
- Karpukhin, V. et al. (2020). Dense Passage Retrieval for Open-Domain Question Answering. arXiv:2004.04906. Google AI.
- Devlin, J. et al. (2018). BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. arXiv:1810.04805. Google.
- Reimers, N. & Gurevych, I. (2019). Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks. arXiv:1908.10084.
- Wang, L. et al. (2022). E5: A New High-Quality Embedding Model. arXiv:2212.03533.
- OpenAI. (2025). Embeddings API Documentation — text-embedding-3-small. OpenAI Platform.
- Johnson, J. et al. (2024). FAISS: A Library for Efficient Similarity Search. Meta Fundamental AI Research.
- OpenAI. (2024). GPTBot Web Crawler Documentation. OpenAI.
- Google. (2020). Understanding searches better than ever before. Google Search Blog.