How Search Engines Use Internal Links: Crawling, Indexing & PageRank Flow
Search engines use internal links in three distinct systems: the crawler follows them to discover new URLs, the indexer uses anchor text to assign topical context to the destination page, and the ranking system uses the link graph to compute PageRank — Google’s original document-importance algorithm patented in 1999 (US 6,285,999) and still in use as of 2026 per Google’s public Search Central guidance. Pages with zero inbound internal links receive no PageRank flow and are crawled less frequently or not at all; these are called orphan pages and are the single most common cause of un-indexed content on large sites.
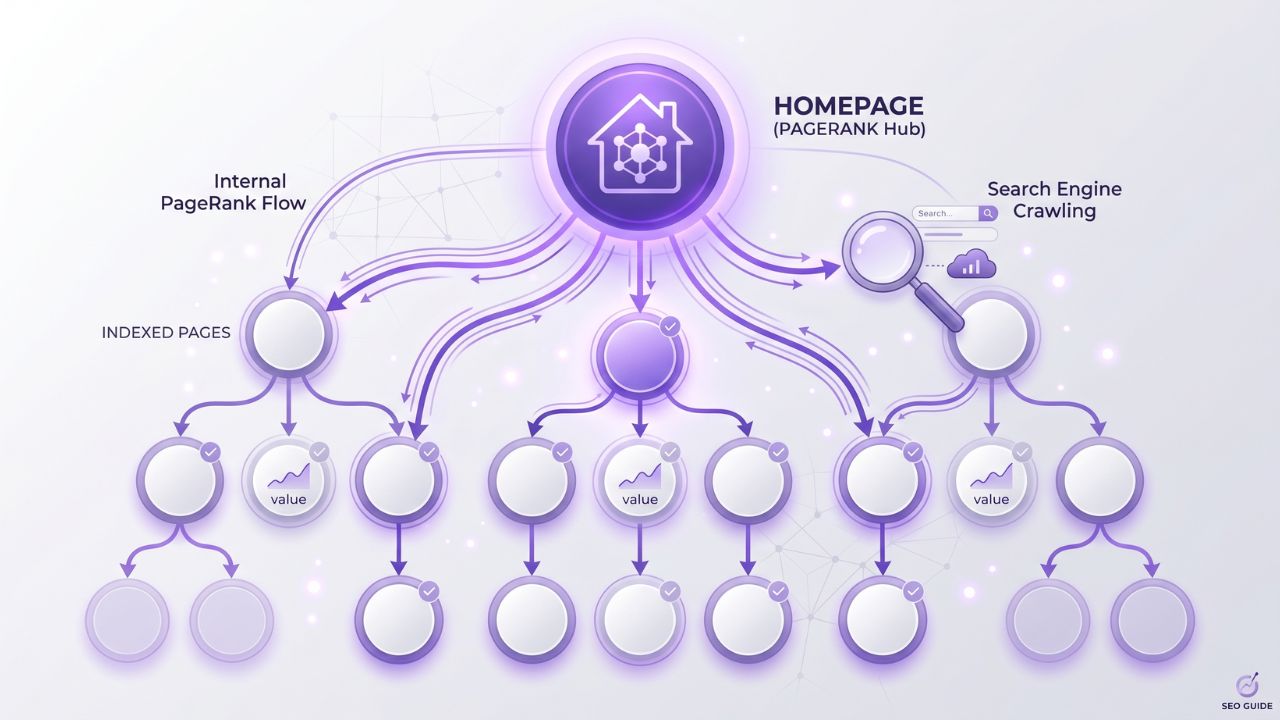
The Three Systems That Read Your Internal Links
Internal links are read by three independent Google systems, each with a different purpose. Understanding which system uses what signal is the foundation of every internal linking decision:
- Googlebot (the crawler) — uses internal links to discover new URLs and to decide which URLs to crawl next. Reference: Google Search Central, “How Google Search Works” documentation.
- The Indexer — uses the anchor text + surrounding context of the inbound link to assign topical signals to the destination page. Reference: Google Patent US 7,716,225 (Reasonable Surfer Model).
- The Ranking System — uses the full internal link graph to compute PageRank, the document-importance score that influences ranking. Reference: Google Patent US 6,285,999 (Original PageRank, 1999) and ongoing Google guidance that PageRank remains in use.
How Googlebot Discovers Pages Through Internal Links
Google’s documented page discovery sequence:
- Googlebot starts from a known URL (your homepage, a sitemap URL, or a URL it has previously crawled)
- It parses the HTML and extracts every
<a href>element that resolves to a crawlable internal URL - Each extracted URL is added to the crawl queue with a priority weighted by the linking page’s authority and crawl depth
- The crawler revisits the queue based on its allotted crawl budget for your site
- New URLs that have no inbound internal links are never added to the queue from internal discovery — they can only be found via your XML sitemap or external backlinks
This is why orphan pages are typically un-indexed: with no inbound internal link, the only discovery path is the sitemap, and sitemaps are a lower-priority signal than the link graph.
How the Indexer Interprets Anchor Text
The Reasonable Surfer Model (Google patent US 7,716,225) describes how Google assigns weight to a link based on its likelihood of being clicked. Key factors:
- Anchor text content — the words inside the
<a>tag are read as a topical signal about the destination page - Position on the page — links higher in the body receive more weight than footer or sidebar links
- Visual prominence — font size, color contrast, and surrounding whitespace affect click likelihood and therefore weight
- Surrounding text — the sentence and paragraph around the anchor text contribute additional topical context
- Repetition on the page — multiple internal links with the same anchor on the same page are counted once in most cases (the first occurrence)
The practical implication: an anchor like “internal linking tool” inside a paragraph about anchor-text optimization sends a much stronger topical signal than the same anchor in a footer “Tools” list.
How PageRank Flows Through the Internal Link Graph
PageRank flows from page A to page B in proportion to:
PR(B) = (1 - d) + d × Σ [ PR(A) / outbound_links(A) ]Where:
PR(A)= the PageRank of the source page (its accumulated authority)d= the damping factor (~0.85), modeling the probability a random surfer clicks a link rather than jumps to a new pageoutbound_links(A)= the total number of outgoing links on the source page (internal + external)
The critical consequence: a page that links to 100 other pages distributes 1/100th of its PageRank to each link target. A page that links to 10 other pages distributes 1/10th to each — 10x more concentrated. This is why high-traffic pages with bloated navigation hurt the ranking of every page they link to. Click depth impact on search rankings is significant when considering the distribution of PageRank. Fewer links within a page can lead to better ranking for those few, while excessive links can dilute authority. This is particularly evident in complex navigation schemes that complicate user experience and hinder site performance.
Why Orphan Pages Get Ignored
When a page has zero inbound internal links:
- Googlebot cannot discover it via crawling (only via sitemap, which is lower priority)
- The page receives zero PageRank flow from the rest of the site
- The indexer has no anchor text signals about what the page is about — it relies only on the page’s own content
- The page is effectively invisible to search rankings even if it’s technically indexed
This is why orphan-page detection is the foundational audit every site needs — and why an internal linking tool like LinkBoss surfaces orphans as one of its primary outputs.
Click Depth: The Other Dimension of Internal Link Authority
Click depth measures how many internal links a user must traverse to reach a page from the homepage:
| Click depth | Indexation likelihood | Typical PageRank inherited |
|---|---|---|
| 0 (homepage) | 100% | 1.0 (baseline) |
| 1 (linked from home) | ~99% | ~0.15–0.25 |
| 2 | ~95% | ~0.05–0.10 |
| 3 | ~80% | ~0.02–0.04 |
| 4+ | <50% — risk zone | ~<0.01 |
Pages buried 4+ clicks deep are crawled rarely and rank poorly. The fix is structural — either move the page higher in the navigation, or build internal links from already-shallow pages.
What Google Has Officially Said About Internal Links
| Source | Statement |
|---|---|
| Google Search Central — SEO Starter Guide | “Internal links connect different pages on your site so that both your users and search engines can find them.” |
| John Mueller, Google Search Office Hours | “Internal links are super critical for SEO. I think it’s one of the biggest things you can do on a website to kind of guide Google.” |
| Google Search Central — Crawl Budget Guide | “Crawl demand depends on… the popularity of URLs on the Internet (and on your site), and how stale they are…” — internal link popularity directly affects crawl demand. |
| Original PageRank Patent (US 6,285,999) | “The link structure of the Web can be used to calculate a quality ranking for each Web page” — confirms internal link graph is part of the ranking computation. |
How LinkBoss Uses Google’s Documented Signals
A modern internal linking tool — like LinkBoss — operationalizes the same signals Google reads:
- Discovers orphan pages (the crawler-discovery gap)
- Suggests semantic anchor text matching destination-page topicality (the indexer signal)
- Balances outbound link count per page to prevent equity dilution (the PageRank-flow signal)
- Surfaces deep pages (4+ clicks from home) for promotion to shallower internal positions
The same patterns that Google’s documentation describes are the patterns a quality internal linking tool automates at scale.
Frequently Asked Questions
Q: Does Google still use PageRank in 2026?
A: Yes — Google has publicly confirmed that internal versions of PageRank remain part of the ranking system, even though the toolbar PageRank metric was retired in 2016. The original 1999 patent (US 6,285,999) and the Reasonable Surfer extension (US 7,716,225) are both still cited in Google’s documentation and engineer interviews.
Q: How many internal links per page is too many?
A: There is no hard cap, but Google’s documented advice is to keep internal link counts “reasonable” — sites with 100+ outbound links per page typically dilute PageRank flow to the point where each link target receives almost no equity. A target of 30–60 internal links per content page (and 25–30 from the homepage) is widely considered the optimal zone.
Q: Do internal links pass PageRank through nofollow attributes?
A: No — rel="nofollow" (and rel="sponsored", rel="ugc") are hints that Google generally respects, meaning the link does not pass PageRank to the destination. However, since 2019 Google has treated these as hints rather than strict directives. Internal links should almost never use nofollow.
Q: How do I tell which of my pages are orphans?
A: The fastest method is a free orphan page checker — it crawls your site and flags every URL with zero inbound internal links. Other methods: cross-reference your XML sitemap against your internal-link map in Ahrefs Site Audit or Screaming Frog.
Q: How does click depth differ from URL depth?
A: URL depth is structural (how many slashes are in the URL path — /category/sub/page/ is 3 levels deep). Click depth is navigational (how many clicks from the homepage). Google cares about click depth, not URL depth — a page at /category/sub/page/ that’s linked from the homepage has a click depth of 1 and ranks accordingly.
References
- Page, L. (1999). Method for node ranking in a linked database. US Patent 6,285,999.
- Google. Large site owner’s guide to managing crawl budget. Google Search Central.
- Google. How Googlebot discovers and crawls pages. Google Search Central.
- Google. Ranking documents using link anchor text and weighted link counts. US Patent 7,716,225.