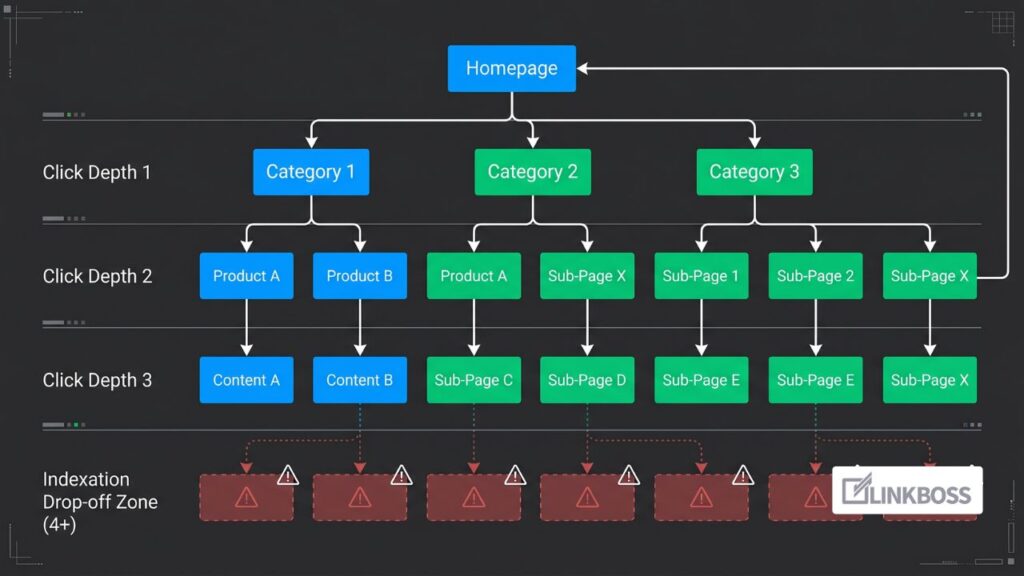
Click Depth & Indexation: Why Pages 4+ Clicks Deep Don’t Rank
Click depth is the number of internal link “hops” required to reach a specific page starting from your homepage. Google’s crawl-budget allocation model assigns exponentially decaying crawl priority to pages the further they sit from high-authority entry points. Pages buried 4 or more clicks deep receive fewer than 50% of the crawl visits given to shallow pages, meaning they frequently fail to enter Google’s index entirely. Because Googlebot navigates your site using a breadth-first link graph architecture, deep URLs are structurally deprioritized and often drop completely below the crawl budget threshold on larger sites.
What Is Click Depth, Exactly?
Click depth—also known as crawl depth—is the minimum number of link clicks required to navigate to a page from the homepage. It is fundamentally different from URL path depth (like /category/subcategory/product/page/), which is merely a text-string structure. Google evaluates the link graph rather than URL patterns to determine crawl habits; if a page with a deep URL path is linked directly from your homepage, its click depth is 1, and Googlebot treats it as a top priority.
- Click depth: Navigational property derived from the actual rendered link graph. It determines what Googlebot follows.
- URL depth: Structural folder organization within the text string. A URL can look deep but remain highly accessible to crawlers if linked strategically.
The Crawl-Budget Allocation Model: Why Depth 4 Is the Danger Zone
Google’s crawl budget for any site is finite. It is primarily driven by crawl demand (how popular and frequently updated a page is both internally and externally) and Crawl efficiency (the structural ease of fetching the page without taxing your server).
The original PageRank formula utilizes a damping factor (typically estimated around 0.85). This models the probability that a user or bot will continue clicking links rather than abandoning the path. As a result, link equity scales down exponentially with every hop. Per the original PageRank patent, link authority effectively halves between depth 3 and depth 4.
Effective PageRank at Depth N ≈ PageRank(Homepage) × 0.85^N| Click Depth | Effective PageRank (% of Homepage Equity) |
|---|---|
| 1 | ~85% |
| 2 | ~72% |
| 3 | ~61% |
| 4 | ~52% |
| 5 | ~44% |
Once you cross past depth 3, the authority signals drop significantly, trailing off into a low-priority crawl status. For massive web properties, this means thousands of pages get locked out of organic indexation entirely.
Why 4+ Click Depth Triggers Indexation Risks
The risks associated with a 4-click threshold are verified by empirical SEO analysis and core algorithmic rules. As PageRank decays, the crawl frequency slows down drastically. If a crawler only evaluates a page once a month, it struggles to see updates, track changes, or maintain stable rankings.
| Click Depth | Estimated Crawl Frequency | Indexation Likelihood | PageRank Inherited |
|---|---|---|---|
| 0–1 | Multiple times per day | ~99% | 0.85–1.00 |
| 2 | Daily to weekly | ~95% | 0.50–0.84 |
| 3 | Weekly to bi-weekly | ~80% | 0.25–0.49 |
| 4 | Bi-weekly to monthly | ~40–50% | 0.10–0.24 |
| 5+ | Monthly to never | <25% | <0.10 |
At 4+ clicks, deep pages suffer from weak anchor text context because the upstream pages pointing to them are already starved for authority. Even if Google discovers the URL via an XML sitemap, it often treats the page as low-value, resulting in poor ranking placement.
Common Causes of Deep Site Architecture
Sites typically slide into high click depths through a few predictable design errors:
- Faceted & Filtered Navigation: E-commerce attributes that generate multi-layered parameters, adding redundant link depth.
- Rigidly Siloed Architecture: Content paths that move solely downward through isolated parent-child categories with zero internal cross-linking.
- Linear Pagination: Large blogs requiring users to click “Next Page” dozens of times to reach historical archives.
- Orphaned Content: A critical threat. When combined with deep site locations, orphan pages stand zero chance of natural organic visibility.
How to Measure and Map Your Site’s Click Depth
Auditing your click architecture requires executing a professional crawl to isolate every asset living at depth 4 or higher. While software like Screaming Frog and Ahrefs can export raw spreadsheet data detailing your crawl depth, visual link modeling is far more practical for finding broken structural patterns.
The LinkBoss Site Visualizer converts this process into an interactive network map. It scans your structural paths, automatically highlighting high-depth nodes and tracing exactly where internal link equity is bleeding off. This lets you inspect large content clusters and see where architectural structural loops are trapping your crawl budget.
How to Flatten Your Architecture: Flattening Content Paths to 3 Clicks
No amount of content adjustments can make up for bad click placement. To bring your pages closer to the homepage baseline, employ these proven flattening techniques:
- Strategic Homepage Placements: Highlight high-value target pages directly on the homepage, or link to key category landing pads at a shallow depth 1 level.
- Hub-and-Spoke Cross-Linking: Build thematic horizontal links between complementary internal posts to transfer link equity across equal levels.
- Deploy Semantic Breadcrumbs: Breadcrumbs establish an explicit hierarchical schema path, ensuring clear navigation routes back to root categories.
The Semantic Silo Builder inside LinkBoss automates this step. Using its Priority Silo configuration, the platform funnels internal link value directly to your most critical revenue pages. By identifying your high-performing pages and forming incoming contextual nodes from shallow hubs, you can systematically pull hidden pages out of the structural danger zone.
Official Statements on Crawl Depth
“Pages that are really far away from the main navigation tend to get crawled less often.” — John Mueller, Google Search Office Hours
| Source | Core Principle |
|---|---|
| Google Search Central — Crawl Budget Guide | Crawl demand relies heavily on internal popularity. Frequent inner links signal structural priority to Googlebot. |
| PageRank Patent (US 6,285,999) | The damping factor acts as a mathematical representation of link degradation over distance, proving authority dilutes at every step. |
References
- Google. Large site owner’s guide to managing crawl budget. Google Search Central.
- Page, L. (1999). Method for node ranking in a linked database. US Patent 6,285,999.
- Google. How Googlebot discovers and crawls pages. Google Search Central.