How AI Crawlers Use Internal Links (GPTBot, ClaudeBot, PerplexityBot)
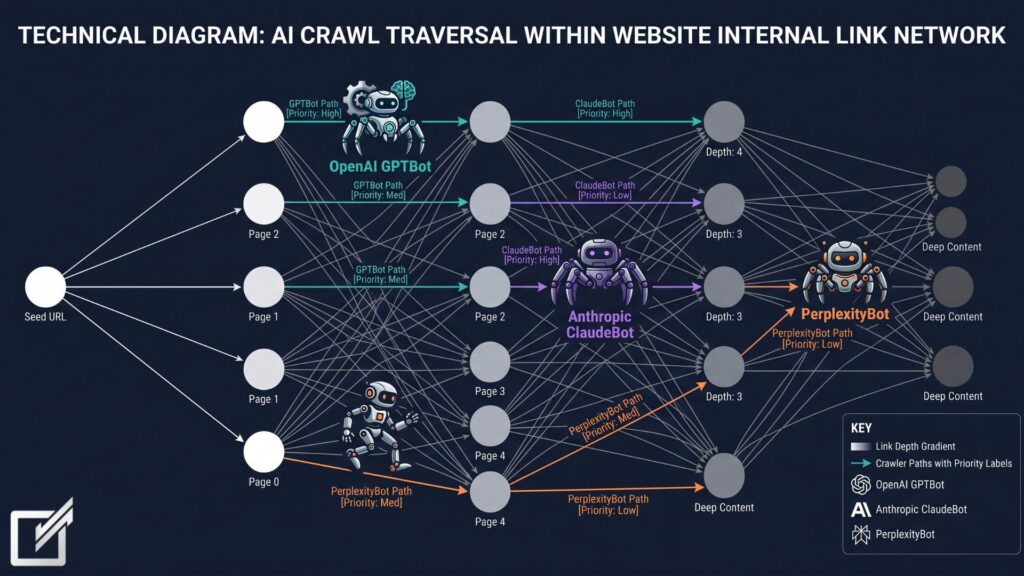
AI crawlers—specifically OpenAI’s GPTBot, Anthropic’s ClaudeBot, and Perplexity’s PerplexityBot—are fundamentally altering how web content is discovered and prioritized. Instead of relying solely on XML sitemaps, these advanced bots treat your internal link graph as a definitive topical authority signal. GPTBot’s technical documentation confirms it uses an adaptive crawl priority system based on link depth from seed URLs, while ClaudeBot weights deep contextual links over sitewide navigation blocks. PerplexityBot cross-references anchor text semantics directly with user query intent vectors to pull real-time source citations.
Unlike Googlebot, which distributes equity via traditional link-graph mathematics like PageRank (US 6,285,999) and the Reasonable Surfer Model (US 7,716,225), AI crawlers evaluate internal links as editorial context nodes. Within an AI-driven data topology, a page with zero inbound internal links is effectively invisible to LLM retrieval and citation layers—no matter how high its raw text quality is. The ideal number of internal links on a page helps search engine algorithms understand its relevance and context. By strategically placing these links, content creators can enhance their visibility and ensure that important pages are easily accessible. This approach not only optimizes SEO but also improves user navigation throughout the site.
How AI Crawlers Discover Pages Through Internal Links
AI LLM scrapers process content through a semantic lens rather than a raw index-building lens. Their crawl behaviors reveal distinct mechanics in how they traverse a site’s structure:
- GPTBot (OpenAI): Discovers new content by mapping internal link relationships, prioritizing assets connected to high-traffic or highly linked core hubs. It strictly respects
robots.txtrules and utilizes the user-agent stringMozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko); compatible; GPTBot/1.3; +https://openai.com/gptbot. Server-level configurations can target its designated IP ranges via its public JSON endpoint. - ClaudeBot (Anthropic): Navigates internal link structures to construct a comprehensive topological map before passing filtered text batches to Claude’s training and live citation corpus. It places a significantly higher weight on contextual links embedded within the main article body than on footer or header links.
- PerplexityBot: Merges traditional crawler loops with dense vector semantic analysis. An internal link naturally placed inside a paragraph dealing with “vector-based internal linking” establishes a clear topical boundary, while a global sidebar link is treated as noise. PerplexityBot focuses heavily on real-time indexing for answer generation rather than long-term foundation model pre-training.
- The Sitemap Constraint: While these bots accept traditional XML sitemaps, they treat them merely as general discovery hints. Isolated URLs found inside an XML sitemap that completely lack natural inbound internal links are consistently bypassed or heavily penalized during context indexing.
Why Internal Links Matter More for AI Crawlers Than Traditional SEO
In traditional Search Engine Optimization, an internal link passes link equity (PageRank) to help pages rank higher in a keyword index. In the era of Retrieval-Augmented Generation (RAG) and AI search engines, internal links act as critical contextual boundaries: Understanding what is a contextual link definition is essential for leveraging the full potential of internal linking strategies. These links provide not only navigation but also context, which enhances user experience and informs search engines about the relationship between content. As a result, mastering this element can lead to improved rankings and increased visibility in search results.
- Implicit Editorial Endorsements: LLM data parsers interpret an internal body link from Page A to Page B as an explicit human validation of topical relevance, signaling that the target document contains supporting depth.
- The Orphan Page Blindspot: Isolated pages containing zero inbound internal links are completely ignored by Perplexity’s real-time citation logic because they lack cross-verified site context.
- Crawl Depth vs. Citation Odds: Link depth from the root directory directly determines whether an AI system surfaces a page. Pages buried 4 or more clicks deep from the home page are rarely processed or cited in real-time answers.
- Knowledge Graph Grounding: The precise semantic anchor text of internal links provides clean, labeled metadata that allows AI systems to properly place and group pages inside their internal knowledge graphs.
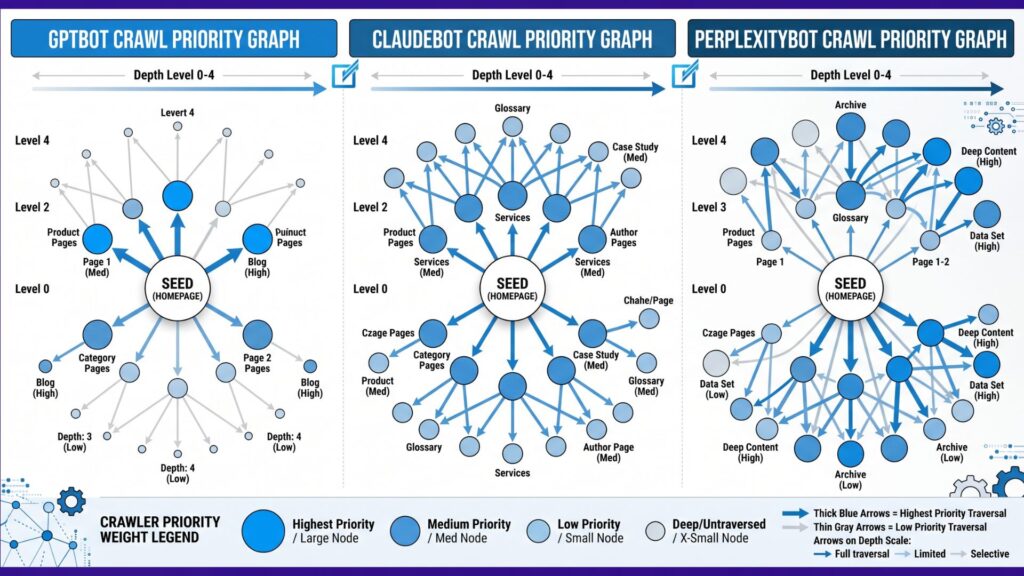
How GPTBot Processes Internal Links (OpenAI’s Published Behavior)
OpenAI’s technical documentation notes specific behavioral constraints that structural webmasters must design around to maximize visibility:
| Signal | GPTBot Behavior | Implication for Internal Linking |
|---|---|---|
| robots.txt Directives | Strictly respects Disallow paths. | Ensure major bottom-of-funnel content isn’t unintentionally blocked within your system rules. |
| Crawl Priority | Favors pages with dense, high-value internal/external link profiles. | Position your core conversational landing pages as primary internal link hubs. |
| Link Depth Impact | Deeply nested URLs are crawled significantly less often. | Migrate toward a flat, highly connected semantic silo structure to accelerate bot discovery. |
| Frequency Calculations | Dynamically adjusts based on visible site update histories. | Frequently updating internal links on older pillar posts alerts the bot to revisit and re-parse newly added spoke content. |
How ClaudeBot Evaluates Internal Link Context (Anthropic’s Approach)
Anthropic’s ClaudeBot relies on advanced natural language processing (NLP) to judge individual links based on their immediate text surroundings:
- Body-Text Superiority: Main body text links carry massive structural weight for topical classification, while boilerplate elements like structural footers, utility navs, and sidebar tags are routinely filtered out.
- Contextual Disambiguation: ClaudeBot analyzes the surrounding sentence structure of an anchor to resolve ambiguous terms, ensuring the true intent matches the target asset.
- Relevance Clustering: Hyperlinks pointing to topically close semantic clusters receive greater programmatic trust than disjointed cross-category links.
- Positional Probabilities: Elements of the Reasonable Surfer model are evident in how ClaudeBot estimates the likelihood of a real user clicking a link based on its location inside the layout, using that probability to scale context weight.
How PerplexityBot Uses Internal Links for Answer Generation
PerplexityBot is heavily tailored to power a live, real-time response interface rather than building massive static indices:
- Dynamic Topical Mapping: Perplexity maps out topical entities using your internal link paths to quickly verify the depth of a domain’s expertise before selecting its content as a trusted source link.
- Pillar-to-Spoke Endorsements: Outbound links originating from recognized pillar hubs down to narrower supporting posts function as strong validation loops for technical search prompts.
- Intent Vector Alignment: Anchor phrases are embedded into high-dimensional vector spaces. Using highly specific anchors like “semantic SEO vector embeddings” helps your page directly match user queries that share that exact intent space.
- Cross-Cluster Discovery: Clean horizontal cross-linking between adjacent topical categories allows PerplexityBot to pull multiple complementary resources into a single multi-layered chat response.
Internal Linking Optimization Checklist for AI Crawler Compatibility
| Action Item | AI Crawler Benefit | Implementation Strategy |
|---|---|---|
| Cap Crawl Depth at 3 Clicks | Guarantees deeper assets remain high on bot discovery queues. | Audit using site visualization tools; construct explicit links from primary pages to deeper nodes. |
| Insert Contextual Body Links | Passes pristine semantic data instead of raw template noise. | Manually inject links from high-authority hub assets directly into detailed spoke articles using descriptive anchors. |
| Remove Internal Nofollow Tags | Prevents bots from suddenly stopping during site discovery loops. | Eliminate legacy rel="nofollow" parameters on all valuable internal informational URLs. |
| Reconnect Definitively Orphaned URLs | Rescues hidden pages from being completely excluded by LLM filters. | Run a automated scan to identify unlinked posts, then use tools like LinkBoss to add contextual, semantically relevant links. |
| Use Specific, Natural Anchors | Gives AI parsers clear, descriptive labels for knowledge graph indexing. | Replace vague phrases like “click here” or “learn more” with highly targeted, descriptive topical phrases. |
How AI Crawlers Compare to Googlebot on Internal Link Processing
| Factor | Googlebot | GPTBot | ClaudeBot | PerplexityBot |
|---|---|---|---|---|
| Primary Discovery Path | XML Sitemaps + Link Graph | Link Graph + Sitemap Hints | Topological site maps built from Link Graphs | Semantic Link Graph + Sitemap mapping |
| Internal Link Weight | PageRank Distribution (US 6,285,999) | Traversal Priority Signal | Editorial Endorsement Weighting | Topical Relevance Context Node |
| Nofollow Treatment | Hint (Since 2019) | Strictly respects as a Directive | Highly likely to treat as a Directive | Respects as an explicit Directive |
| Anchor Text Parsing | Reasonable Surfer + BM25 Algorithmic Matching | High-level Semantic Context Evaluation | Semantic Context + Coreference Resolution | Full High-Dimensional Semantic Embedding |
| Crawl Depth Sensitivity | Directly modifies crawl frequency and page rank | Determines Priority Weighting inside queues | Alters editorial value and confidence score | Directly shifts citation selection probability |
| Orphan Page Handling | Discovers via XML sitemap (crawled with low priority) | Effectively Invisible | Extremely Low Priority Processing | Effectively Invisible |
Why Topical Authority in Internal Linking Directly Affects AI Citation
Modern AI search engines prioritize pages based on structural authority. They favor content that is fully integrated into your site’s architecture over standalone articles:
- Intra-Cluster Density: Pages that are naturally cross-linked with multiple relevant articles inside the same topical silo.
- Structured Hub-and-Spoke Architecture: Sites built with clear, defined topical boundaries and structured semantic hierarchies.
- Upstream Hub Validation: Target content that is supported by internal links from major, high-authority resource pages.
- Horizontal Cluster Bridges: Smart cross-linking between adjacent topical areas that showcases the total depth of your domain’s knowledge.
The structured topical authority signals you establish via your internal links map directly to your citation metrics within AI response platforms. Isolated pages with no inbound links lack the internal validation required by LLMs, meaning they are systematically deprioritized by all major AI platforms. Developing a highly structured internal linking framework is essential if you want your brand to be cited as an authoritative source in AI-generated answers.
Check out our comprehensive AI Internal Linking hub to see how NLP frameworks, dense vector embeddings, and semantic searches are replacing old-school keyword matching plugins. Vector embeddings for semantic understanding allow machines to better grasp the nuances of human language. This advanced technique enhances the relevance of search results by considering the context and meaning behind queries. As a result, users experience more intuitive and efficient interactions with digital content.
Frequently Asked Questions
Do AI crawlers like GPTBot and ClaudeBot follow internal links the same way Googlebot does?
No. AI crawlers interpret internal links primarily as editorial contextual endorsements within your content topology. Googlebot, by contrast, uses them for algorithmic PageRank distribution ($US 6,285,999$) and raw crawl queue management. GPTBot, ClaudeBot, and PerplexityBot place significantly more weight on contextual body links than on sitewide navigation blocks, and they use anchor text semantics to map topical relevance rather than relying strictly on keyword match frequencies.
Can I block AI crawlers from my site with robots.txt, and will that hurt my traditional SEO?
Yes, you can block AI crawlers by using explicit Disallow directives within your robots.txt file—GPTBot and ClaudeBot fully respect these rules. Doing so means your pages will be excluded from LLM generation models and real-time response answers. However, blocking them will not hurt your traditional Google organic search rankings; Googlebot will continue to crawl and index your content normally.
How does click depth affect whether an AI crawler cites my page?
Click depth heavily impacts citation probability. Pages buried 4 or more clicks from the home page receive minimal traversal priority from AI bot queues. GPTBot and PerplexityBot drop deep URLs from their active crawl schedules, and Perplexity’s real-time citation system strongly favors shallow pages that have multiple contextual links from core hub articles.
What internal link anchor text works best for AI crawler optimization?
Highly descriptive anchor text that naturally frames the target page’s core topic yields the best results across GPTBot, ClaudeBot, and PerplexityBot. Precise phrases like “vector embedding cosine similarity for SEO” provide clear semantic data, whereas generic variations like “click here” or “read more” offer zero usable context and are ignored by AI citation filters.
Are orphan pages ever cited by AI search engines like Perplexity?
Orphan pages—URLs completely devoid of internal links—are effectively invisible to PerplexityBot. Perplexity builds its real-time response index from domains where content shows clear internal validation via the link graph. An unlinked page can only be found via direct external backlinks or sitemap discovery, neither of which carries the contextual authority needed for AI citations.
How does internal linking for AI crawlers differ from optimizing for Google AI Overviews?
While Google AI Overviews and Perplexity both employ deep semantic processing, their foundational ranking weights differ. Google AI Overviews still relies heavily on core Google search signals alongside modern vector semantic matching. Perplexity focuses on immediate answer-generation relevance. Both ecosystems benefit from structured hub-and-spoke models and descriptive anchors, but Perplexity’s citation engine is more sensitive to internal link structures and topical clustering.
References
- OpenAI. GPTBot — OpenAI Platform Documentation. Platform.openai.com.
- Perplexity. Perplexity Crawlers — Perplexity Documentation. Docs.perplexity.ai.
- Google. Large site owner’s guide to managing crawl budget. Google Search Central.
- Page, L. (1999). Method for node ranking in a linked database. US Patent 6,285,999.
- Google. Ranking search results by click distance from valuable pages. US Patent 7,716,225 (Reasonable Surfer Model).